Исправляем кодировку текстового файла в Linux
prolinux
| Опубликован: | 2024-03-31T03:03:14.629656Z |
| Отредактирован: | 2024-03-31T03:03:14.629656Z |
| Статус: | публичный |
Текстовый файл в современном компьютерном мире представляет из себя самый обычный набор байт, который посредством наложения на него соответствующей ему кодовой страницы - кодировки - преобразуется в простой текст - набор упорядоченных определённым образом графических символов того или иного алфавита. Кодировок сегодня известно достаточно много, ибо исследователи разных лабораторий шли параллельными путями на заре становления компьютерной школы. В этом выпуске блога я покажу простой способ, как преобразовать текстовый файл одной кодировки в текстовый файл другой кодировки. В примере рассмотрено преобразование текста CP1251 - стандартной кодировки операционной системы Windows, в UTF-8 - стандартную кодировку операционных систем с ядром Linux с помощью стандартного средства языка программирования C - программы iconv.
Диагностика проблемы
С развитием глобальной паутины каждый пользователь современного компьютера получил возможность обмена файлами с другими пользователями сети. Проблема заключается в различии аппаратных и программных платформ, используемых разными пользователями. У одного пользователя компьютер фирмы Dell, на котором установлена операционная система MS Windows, он с его помощью создал текстовый файл и разместил на каком-нибудь ресурсе сети. Другой пользователь на другом конце света загрузил этот файл на свой компьютер почти неизвестного китайского бренда и пытается прочесть его средствами операционной системы с ядром Linux - и у него это не получается с первого раза.
Давайте рассмотрим обычную для наших сетевых реалий ситуацию... Мы загрузили из сети образ CDDA, который представляет из себя набор файлов. В этом наборе есть текстовый файл с расширением .cue. Вы пытаетесь прочесть этот файл на компьютере с операционной системой с ядром Linux, например Debian, с помощью консоли и консольной команды cat. И вот что вы увидите в подавляющем большинстве случаев, внимание на снимок экрана.
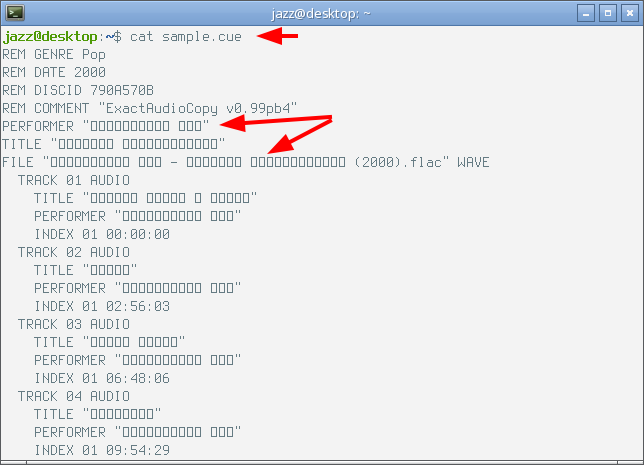
Что произошло? Программа cat прочитала набор хранящихся в указанном ей файле байт, наложила на него кодовую страницу своей локали и выдала полученный текст на экран. В данном конкретном случае кодовая страница текстового файла не совпадает с кодовой страницей используемой локали, у операционной системы нет средств, чтобы отобразить некоторые символы неизвестной ей кодовой страницы, и она вывела в терминал на месте этих символов символ прямоугольника. В итоге пользователь не может прочитать содержимое файла и сильно расстраивается.
Решение проблемы
Расстраиваться конечно же не стоит... Ларчик открывается просто.
Давайте определим кодировку текущей локали, для этого у нас есть специальная команда - locale.
$ locale
LANG=ru_RU.UTF-8
LANGUAGE=
LC_CTYPE="ru_RU.UTF-8"
LC_NUMERIC="ru_RU.UTF-8"
LC_TIME="ru_RU.UTF-8"
LC_COLLATE="ru_RU.UTF-8"
LC_MONETARY="ru_RU.UTF-8"
LC_MESSAGES="ru_RU.UTF-8"
LC_PAPER="ru_RU.UTF-8"
LC_NAME="ru_RU.UTF-8"
LC_ADDRESS="ru_RU.UTF-8"
LC_TELEPHONE="ru_RU.UTF-8"
LC_MEASUREMENT="ru_RU.UTF-8"
LC_IDENTIFICATION="ru_RU.UTF-8"
LC_ALL=
Как мы видим из выхлопа этой команды в терминал, в терминале установлена русскоязычная локаль UTF-8. Это значит, что программа cat, читая предложенный ей файл, пытается наложить на полученные из файла байты эту кодовую страницу - UTF-8 - и отобразить полученный текст с помощью установленного в системе шрифта, соответствующего этой кодовой странице.
А теперь давайте определим кодовую страницу файла sample.cue, который мы пытаемся прочесть с помощью программы cat. Сделать это можно с помощью программы uchardet - стандартного детектора кодировок. В операционной системе Debian установить эту программу можно пакетным менеджером apt.
$ sudo apt install uchardet
Вот как выглядит вызов этой команды.
$ uchardet sample.cue
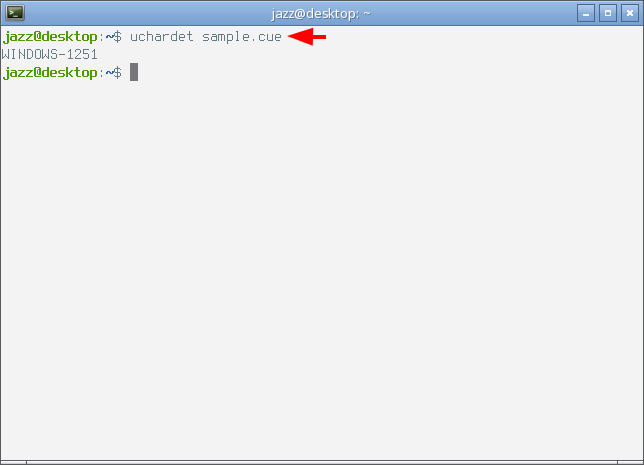
И что же мы видим..? Текстовый файл sample.cue закодирован кодовой страницей CP1251, которая является стандартной для операционных систем семейства Windows. А мы пытаемся прочесть его с кодовой страницей UTF-8 - это всё равно, что пытаться разговаривать с жителем Поднебесной на русском языке. Отсюда и прямоугольники в выхлопе программы cat, которые мы видели чуть выше. Следовательно, решение у проблемы может быть только одно, необходимо перевести исходный текстовый файл с кодовой страницы CP1251 в кодовую страницу UTF-8.
Средства для решения проблемы
Решить обозначенную проблему можно разными средствами. Можно воспользоваться текстовым редактором и перекодировать текст в нём. Но, поскольку мы находимся в консоли, удобным будет решение, которое позволит не снимать руки с основной позиции на клавиатуре.
В любой операционной системе с ядром Linux базовым, встроенным в систему языком программирования является C. В стандартной библиотеке этого языка программирования есть средство для преобразования текста одной кодировки в текст другой кодировки. Это средство реализовано в исполняемом модуле iconv, который установлен по-умолчанию в любой системе с ядром Linux в рамках пакета libc-bin. iconv - это консольная команда, встроенную справку можно посмотреть с помощью ключа --help прямо в терминале.
$ iconv --help
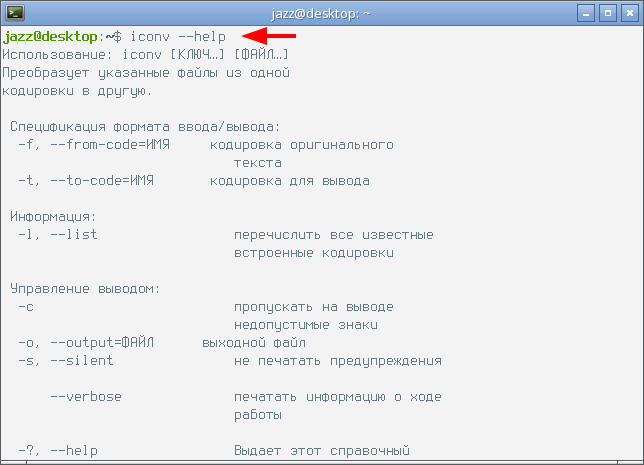
В соответствии с полученной справкой, команда для преобразования текстового файла из кодировки CP1251 в кодировку UTF-8 будет иметь следующий вид:
$ iconv -f WINDOWS-1251 -t UTF-8 -o sample~.cue sample.cu
Здесь я указал следующие ключи:
-
-f WINDOWS-1251- задал кодировку исходного файла, которую получил с помощью программы uchardet; -
-t UTF-8- задал желаемую кодировку полученного в результате такого преобразования файла; -
-o sample~.cue- указал программе имя файла, куда нужно записать полученные в результате обработки данные; -
sample.cue- указал имя исходного файла.
В результате выполнения этой команды никакого выхлопа на терминал не будет. Но в текущем рабочем каталоге появится новый файл с именем sample~.cue. Давайте посмотрим на его содержимое, внимание на снимок экрана.
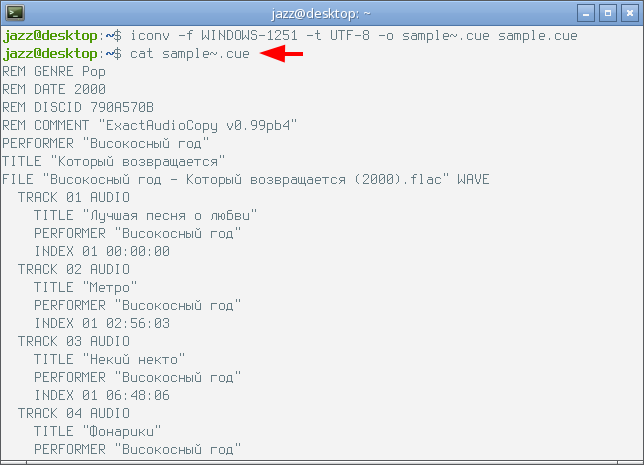
В итоге мы видим, что программа cat отобразила в своём выхлопе содержимое полученного в результате работы программы iconv файла, и этот выхлоп можно читать, все знаки русского алфавита в тексте отображаются адекватно, а это значит, что цель этой демонстрации полностью достигнута.
Замечание: в команде iconv с помощью ключа -o я указал имя нового файла, в итоге, исходный файл остался нетронутым, а программа создала новый файл с заданным именем. Если в ключе -o задать имя исходного файла, то он будет перекодирован и переписан на диске компьютера.
Вывод
Для преобразования текстового файла из одной кодировки в другую совершенно не обязательно открывать графический текстовый редактор и возить по экрану курсор мыши. В любой операционной системе с ядром Linux есть консольная команда (iconv), с помощью которой задуманное преобразование можно сделать быстро и не снимая рук с клавиатуры компьютера. Обязательным этапом при достижении цели будет предварительное определение кодировки исходного файла с помощью программы uchardet.